안녕하세요!!
베키입니다!!

오늘은 R과 Brightics를 사용하여
ranicafe 의 커피 판매량 데이터를 로드하여,
커피 판매량 데이터의 이상치를 찾고,
제거해보도록 하겠습니다!!
이상값 탐지 및 제거에 대한 내용은 아래 링크 튜토리얼에서 참고하였습니다!!
https://www.brightics.ai/kr/docs/ai/s1.0/tutorials/11_py_outlier_detection?type=insight

오늘은 R과 Brightics를 모두 사용해서
이상값을 찾고 제거 해보도록 하겠습니다!
이상값 탐지에 사용한 커피 판매량 데이터는 제가 따로 만든 데이터 입니다!!
여기서 잠깐!
이상값??
상한 사분위수(75%)를 기준으로 1.5 사분위 범위보다 크거나
하한 사분위수(25%)를 기준으로 1.5 사분위 범위보다 작은 값!
을 흔히 이상값으로 정의합니다!!
일단 R로 먼저 커피 판매량 데이터의 이상값을 찾고, 제거하도록 하겠습니다!

먼저, R 스크랩트를 작성해보았습니다!

순서는 위의 스크립트를 보면 어떤 식으로 제가 이상값을 찾고 제거할 지 알겠죠??ㅎㅎ
아래부터는 실제로 작성한 스크립트를 콘솔창에서 실행시킨 화면입니다!!

먼저 정확히 데이터 파일(csv) 속성의 주소를 입력해서 데이터를 불러옵니다!
경고메세지가 뜨지만, 일단 무슨 문제인지 구글에 검색해봐도 모르겠기에,,, skip
skip해도 데이터 불러오는데는 이상이 없습니다!
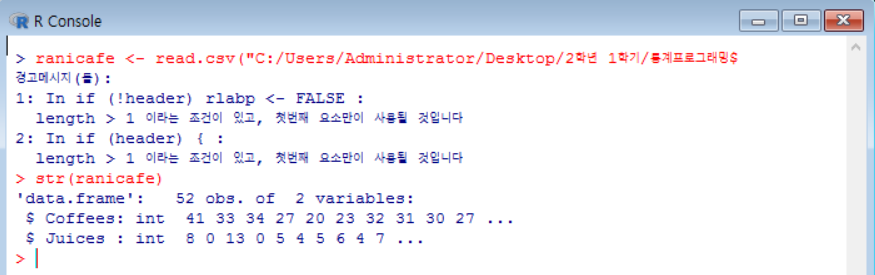
ranicafe 데이터가 Coffees 와 Juices 칼럼으로 구성 되 것을 알 수 있습니다
데이터 속에 있으면, 요약 통계량을 알 수가 없기에,
결측값을 먼저 제거 해주었습니다.

그리고 커피 판매량 값에 대한 이상치를 찾을 것이기에,
rc라는 변수를 생성해주었습니다!

정말 간단하게 요약 통계량을 계산해보려고 하는데요!
summary()함수를 사용해서 요약통계량(평균, 사분위수, 중앙값, 최솟값, 최댓값)을 계산해줍니다!

위 처럼 요약 통계량이 산출되서 나온 것을 알 수 있습니다!
실제로 상자도표(boxplot)를 그려서 커피 판매량 값이 어떻게 분포하는지 알아보았습니다!

평균이 극단값에 영향이 많이 받았다는 생각이 들정도로,
하한 사분위수(25%) 아래에는 이상치가 없지만,
상한 사분위수(75%) 위에는 눈에 띄는 극단값, 이상치가 있는 것을 알 수 있습니다!

실제로 이상치가 몇 인지 탐색해보니,
상한 사분위수(75%) 위로 3개의 이상치 100, 60, 80 이 존재합니다!
이제 이상치는 찾았고, 제거해야겠죠?

이렇게 상한 사분위수(75%) 위의 이상치를 NA (결측값)로 바꾸어 제거해주고,
다시 상자도표를 그려보면,
오른쪽의 그림처럼 이상치가 없는 데이터의 분포를 띔을 알 수 있습니다!!
이번에 Brightics Studio를 사용해
같은 커피 판매량 데이터 속 이상치를 찾고 제거해보겠습니다!

미리 말하지만,,,,
정말 간단합니다ㅎㅎㅎ
R코드를 왜 작성하고 있었나,,,라는 생각도 드는 것 같네요 ㅎㅎㅎ

'커피 판매량'이라는 프로젝트를 생성해줍니다!
그리고 그 안에 '커피 판매량의 이상값 탐지'라는 모델을 만들어 줍니다!
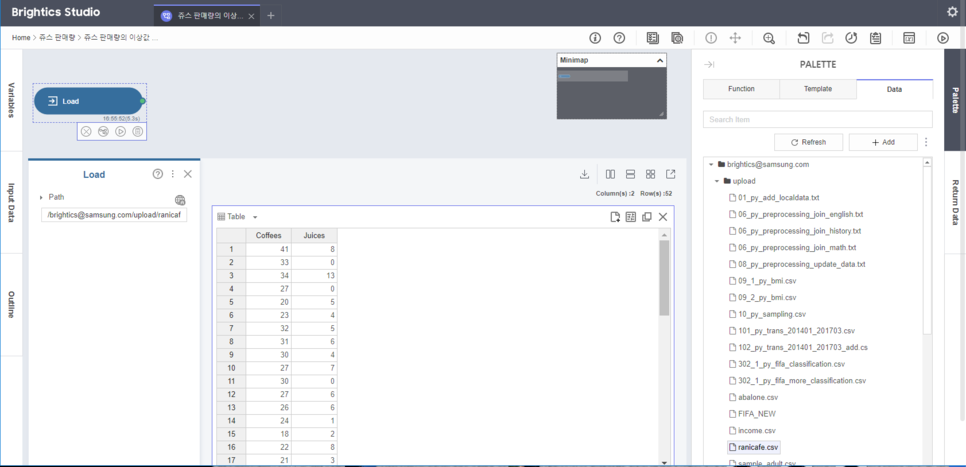
위의 R실습에서 썻던 똑같은
Ranicafe 데이터를 load해줍니다!
일단 요약통계량을 살펴보고자,
우리가 이상값을 찾을 커피 판매량은 double 형의 데이터기에,
Statistic Summary 함수를 사용해 요약통계량을 산출해보겠습니다!

그러면 옆과 같이 요약통계량(평균, 중앙값, 분산, 최솟값, 최댓값, 사분위수)등 등을 알 수 있습니다!
또한 null값이 1개 있다는 것을 알 수 있는데요!!
※당황스럽게도,,, 사분위수(q1,q3) 와 IQR 지수는 계산이 안되었는데,,,
그 이유가 null값이 있어서 그런 것 같습니다!
이렇게 요약통계량을 알았다면, 전체적인 데이터 셋이 어떨지는 대충 감이 잡히는데요,
이제 이상치를 확인하고 제거해보겠습니다!

Outlier Detection (Tukey/Carling) 함수를 사용하면,
한 번에 이상치가 제거되는 데요!!
정확히 몇 개가 제거 되었는지 보면,
Row:52 -> Row:49로 총 3개의 이상치가 제거 된 것을 알 수 있습니다!!
그리고 실제로 하나하나 대조를 해보아도!! 위의 R로 실습한 것과 정확히 일치하는
60, 80, 100의 커피 판매량 값이 제거된 것을 알 수 있습니다!!

R에서 상자도표를 그려서 이상치를 확인했던 것처럼,
Brightics Studio에서도 이상치를 제거하기 전의 데이터로 상자도표를 그려보았습니다
실제로 이렇게 3개의 이상치가 있는 것을 알 수가 있습니다!!
이렇게 R과 Brightics Studio를 사용해서
커피 판매량 데이터의 이상치를 파별하고 제거하는 시간을 가져보았습니다!!

저는 R과 Brightics 의 차이를 알아보려고, 이번 실습을 진행해보았습니다.
제가 느껴보기엔,,,,,,,,,,,,,,,,,
▶ R이 전체 결과를 단순히 계산하기에는 속도 면에서는 훨씬 빠르고,
▷ Brightics 는 단계별로 수행하면서 데이터 결과를 시각적으로 알 수 있어서 좋고,
▶ R은 데이터 시각화에 있어서 매우 떨어지지만,
▷ Brightics의 chart setting은 매우 뛰어납니다,
▷▷ 또한, Brightics는 코딩 없이 간단하게 mapping으로 구성된다는 점!!
이 점이 브라이틱스를 사용하는 유저 입장에서 가장 중요 포인트라고 생각합니다!!
이렇게 이상값 탐지 실습을 마치겠습니다!

#브라이틱스 #Brightics #Studio #이상값 #탐지 #제거 #데이터전처리시리즈 #마지막 #시리즈 #대학생 #서포터즈 #데이터분석 #AI #summary #이상치 #outlier #dectection #데이터 #전처리 #R #실습 #비교 #브라이틱스실습 #커피 #판매량 #튜토리얼 #참고 #실습데이터셋 #삼성SDS #노코딩



