안녕하세요!!
베키입니다!!

오늘은 요즘에 부쩍 늘고 있다는,,,,ㅠㅠ
당뇨병에 관한 얘기를 해볼까 합니다!!
오늘의 주제는!!!
피마 인디언 당뇨병 자료로 본
BMI지수(체질량 지수)와 여러 신체 수치들의 상관관계 분석과
이로 분류분석한 20대 당뇨병의 주 영향요인 찾기입니다!!

Brightics를 사용한 상관관계 분석을 위해 아래의 링크를 참고하여 공부했습니다~~
참고해주세요~~(피마 인디언 데이터도 탑재됨!)
https://www.brightics.ai/kr/docs/ai/s1.0/tutorials/71_py_bp_bmi?type=insight
피마 인디언 데이터는 사실,,,
위의 링크에도 있지만 ML, DL 하시는 분들은 한 번쯤은 사용해봤을 텐데요!
바로 Kaggle의 유명한 데이터 셋입니다!!

https://www.kaggle.com/uciml/pima-indians-diabetes-database
kaggle들어가셔서 데이터셋을 다운 받아도 되고!!
'난 Null 값이 싫다ㅜㅜ...' 하시는 분들은!!!
위의 Brightics 링크로 가셔서 null값이 없는 깔끔한 데이터를 다운받아 사용해도 됩니다!!
저는 '피마 인디언 당뇨병 예측'이라는 프로젝트를 생성해주었습니다!

그리고, 그 안에 '피마 인디언 당뇨병 예측'이라는 모델을 넣어주었는데요!
참고로!!
예측! 이라는 제목과는 다르게
분류 모델을 사용한 점!! 양해 부탁드립니다 ㅎㅎ
예측을하려고 모델을 만들었는데, 결국 마지막은 분석으로 끝났네요 ㅎㅎ
그리고 위의 링크에서 피마 인디어 당뇨병 데이터를 다운 받고, Brightics로 load해줍니다!

데이터의 구성 변수은 아래와 같은데요!!
pregnant(Double) : 임신횟수
glucose(Double) : 경구 포도당 내성검사 2시간 혈장 포도당 농도
diastolic(Double) : 이완기 혈압
triceps(Double) : 삼두근 피부 두겹 두께
insulin(Double) : 2시간 혈청 인슐린
bmi(Double) : 체질량 지수
diabetes(Double) : 당뇨 직계 가족력
age(Double) : 나이
type(Double) : 5년 이내 당뇨병 발병 여부
과연 여기서 어떤 칼럼이 가장 type(당뇨병 발생 여부)와 관련이 높을까요??
일단,
Brightics를 사용해 상관관계를 어떻게 파악할 수 있는지!
BMI 지수와 나머지 변수들과의 상관관계를 분석을 배워보겠습니다!!
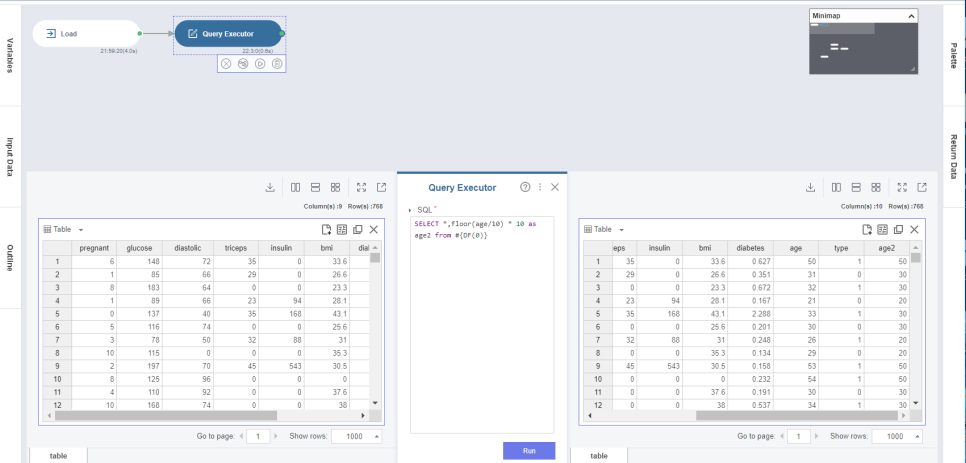
Query Executor를 사용해 위와 같은 SQL 코드를 입력하고 실행해주면,
age 데이터가 20~29 라면 20으로 바뀌어 age2 칼럼으로 저장됩니다!
이런 식으로 20,30,40,50,60, 70 대로 데이터를 맞추어주는 작업을 해줍니다!

Statistics Summary 를 사용해 값들의 요약통계량을 한 번 알아봤습니다!
groupby : type으로 설정하여, 당뇨병 발생에 따라 어떤 신체 수치를 띄는지 알아보았는데요!
일단,
당뇨병을 걸린 사람이 안 걸린 사람 보다
▶ 평균 나이가 7살 정도 많고,
▶glucose라는 혈장 내 포도당 농도가 30정도 높고,
▶Bmi 지수도 5정도 높고,
▶인슐린 수치도 30정도 높고,
뭔가,,, 당뇨병 걸린 사람들은 전체적으로 신체 수치가 많이 높습니다.

Correlation 1 함수를 사용해 연령대별로 모든 변수들에 대해 서로의 Pearson 상관계수를 구했습니다!
20대에 관련해서 좀 더 자세히 상관계수를 들여다 보겠습니다!
(실제로 결과로 나온 상관계수 값인데요!)



20대는!
bmi지수와 triceps(삼두근 피부 두겹 두께), distolic(이완기 혈압)과 상관성을 가지고 있고,
인슐린 값과 glucose(포도당 수치)와 상관성을 가지고 있고,
사실상 두 값이 모두 0.3에 가깝기에 약한 양의 상관관계를 띄고 있습니다.
본격적으로 20대의 당뇨병 환자들은 어떤 신체 수치와 관련이 있는지 알아보겠습니다!

Filter 함수를 사용해, age2==20인 즉, 20대의 데이터만 필터처리 했습니다!

그 상태로 20대의 모든 값에 대해서 상관관계를 분석해보닏,
앞에서와 당연히 같은 결과를 보여줍니다 ㅎㅎㅎ
위와 다른 것을 확인하자면,
type도 상관관계 input column으로 넣은 것인데요!
【type(당뇨병 발생 여부)는 glucose(포도당 수치)와 0.48이라는 가장 높은 양의 상관성을 보여주고 있습니다!!!】
【type(당뇨병 발생 여부)는 bmi 지수와도 0.34이라는 양의 상관성을 보여주고 있습니다!!!】
즉!
20대의 당뇨병 발생에 있어,
신체의 포도당수치와 bmi지수가 연관이 있다는 것인데요!
그럼 여기서!!
실제로 당뇨병인지 아닌지 분류에 포도당 수치와 bmi지수가 어느 정도 연관이 있는지
데이터를 실제 분류해보면서 알아 보겠습니다.

Split Data 함수를 사용해,
20대 데이터를 type에 맞추어 7:3으로 split 해주었습니다!

그리고 모든 칼럼을 다 넣어서 RandomForestClassiferTrain 함수를 사용해 학습을 시켰습니다~~
여기서 분류할 label column은 type이겠죠?ㅎㅎ
Feature Importance에 보면, glucose (포도당 수치)가 당뇨병 여부 분류에서 가장 중요한 것을 알 수 있습니다!

또한 다시 만든 모델로 test데이터 적용해서 분류 학습을 시켰습니다!!

결과적으로 0.80833333 이라는 정확도를 가지고 당뇨병을 분류했는데요!!!
오늘은 제가 말하고 싶은 것은 Random Forest 사용하는 것이 아닙니다!!
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
상관관계 분석으로 파악한 주요 변수가
실제로 분류를 통해서 본 결과에서도
중요한 요인이 이라는 것!!!
※※※※※※※※※※※※※※※※※※※※※※※※※※※※※※
제가 생각했을때,
상관성 분석은 예측, 분류를 하는데 있어
피쳐 선택에
보충하는 정보를 주는 정도의 효과가 있는 분석이라고 생각합니다!!
너무 상관성에 의존해서 데이터를 보는 것은 옳지 않고,
상관성은 확인하고 EDA 수준에서 히트맵 이미지정도로 확인하고 넘기는 단계로 사용해야 합니다!

수고하셨습니다~~
#Brighitcs #AI #당뇨병 #상관분석 #상관성 #20대 #당뇨병환자 #분류 #무슨 #요인이 #중요 #데이터 #분석 #데이터분석 #대학생 #서포터즈 #RandomForest #분류 #상관성은 #거둘뿐 #EDA #브라이틱스 #SNS #데이터사이언스



