안녕하세요!!
베키입니다!!!

이번 포스팅에서 전체적으로 어떻게 전처리를 했는지!!!
보여드리려고 합니다!!!!

<채널 별 전처리>
1단계 : publishedDate(업로드날짜)를
python Script를 사용해, 깔끔하게 변환!!

2단계 : 변환된 publishedDate(업로드날짜)를
python Script를 사용해, 깔끔하게 업로드 날짜 간격 구하기!

위의 스크립트에 이렇게 python 코드만 바꾸면 완료!!
3단계 : 채널별로 구독자수가 다르기에, Normalization function을 사용해
comments, views, likes, dislikes 수는 다 채널 별로 각각 MinMax Scaling 화 하기!!

보시면 이런게
0~1 사이의 값들로 스케일링해서 다른 채널끼리 비교가 가능해졌습니다!!
4 단계 : 결측값 채우기!!!
간혹 결측값이 있는 경우가 있습니다.
그럴 경우에는 Brightics studio의

이 null 값 채우는 function을 사용하면 되겠죠!!!
<분야 별 전처리>
위처럼 개별적으로 전처리가 끝났다면!!!
Join을 사용해서
채널 별로 데이터를 합치면 됩니다!!

이런식으로 16개의 운동채널을 다 합치면 됩니다!!
다합쳤다면!!!
1단계 : 전체적으로 영상 제목의 text데이터에서
토큰화 한 후!! stopword 제거까지!! 수행!!
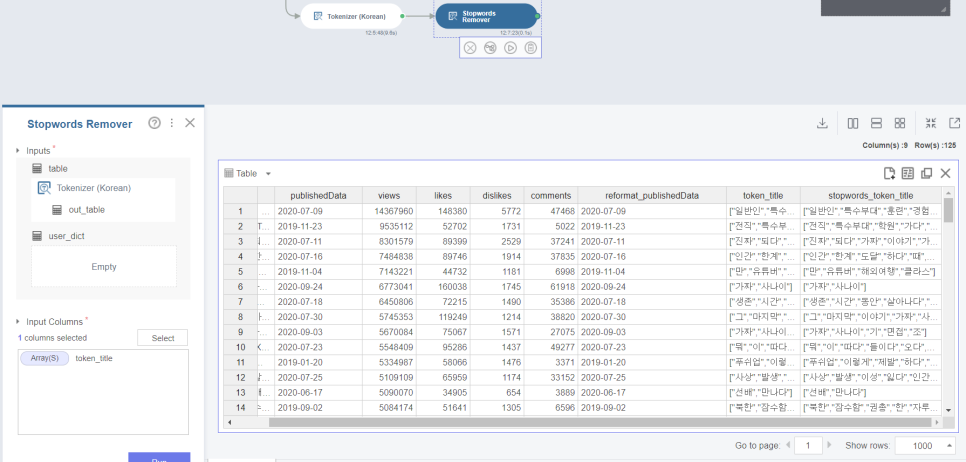
이렇게 Brightics에서 지원되는 Korean tokenizer 로 영상 제목 데이터를 다 조각조각 자르고,
Stopwords Remover로 자르면!!
이렇게 아래 처럼 워드 클라우드로 키워드를 뽑아 자주 사용된 단어를 볼 수가 있어요 ㅎㅎ

워드 클라우드 뽑을려고 텍스트 데이터를 전처리 한거는 아닙니다 ㅋㅋㅋ
다음주에 진행할 텍스트 마이닝 관련해서 전처리가 필요해서 수행한 과정들입니다!!
2단계 : '좋아요'와 '싫어요'의 상대지수 계산 -> 상대적인 값을 사용
'좋아요'수/'싫어요수' = 상대지수
이렇게 계산해서 싫어요수 대비 좋아요수를 계산!!
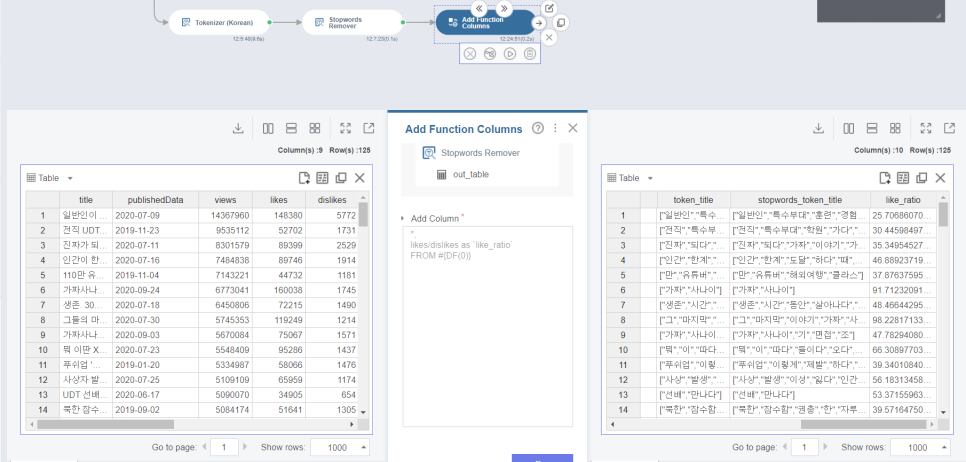
이렇게 저번주에 코드상으로 표현했던 좋아요/싫어요 값을
Brightics의 Add Fuction Columns를 사용해서 구해봤어요!!!
진짜로!
이게 너무 편해요!!
Add Function Columns 함수 클릭
-> 새로운 칼럼 이름 입력, likes/dislikes입력
만 하면 끝!!
진짜 편하죠??
저번주에 코드 치면서 하고 있었는데,,,,
바로 Brightics 키고 할 걸 그랬어요 ㅎㅎ
이렇게 이번주 포스팅을 마치겠습니다!!
#Brightics #AI #데이터분석 #유튜브 #데이터 #전처리 #총합본 #합치기 #오류 #문제해결 #스케일링 #정규화 #join #업로드 #날짜 #계산 #파이썬 #Script #우수한 #기능 #사용 #브라이틱스 #삼성SDS #크롤링 #개인미션 #텍스트전처리 #토큰화 #데이터사이언스 #소프트웨어 #응용통계 #EDA



